- October 16, 2023
- Posted by: Venkatesh Chintha
- Category: Data & Analytics

Abstract
Pre-trained models based on Transformers have achieved exceptional performance across a spectrum of tasks within Natural Language Processing (NLP). However, these models often comprise billions of parameters, resulting in a resource-intensive and computationally demanding nature. Consequently, their suitability for devices with constrained capabilities or applications prioritizing low latency is limited. In response, model compression has emerged as a viable solution, attracting significant research attention.
This article provides a comprehensive overview of Transformer compression, centered on the widely acclaimed BERT model. Within, we delve into the most recent advancements in BERT compression techniques, offering insights into the optimal strategies for compressing expansive Transformer models. Furthermore, we aim to illuminate the mechanics and effectiveness of various compression methodologies.
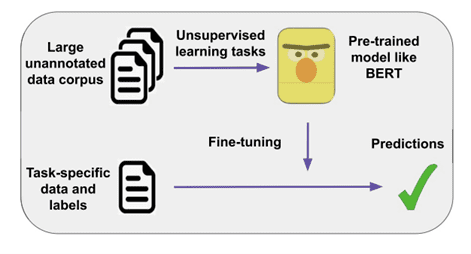
Fig. Pre-training large scale models
Introduction
Tasks such as sentiment analysis, machine reading comprehension, question answering, and text summarization have benefited from pre-training large-scale models on extensive corpora, followed by fine-tuning for specific tasks. While earlier methods like ULMFiT and ELMo utilized recurrent neural networks (RNNs), more recent approaches leverage the Transformer architecture, which heavily employs the attention mechanism.
Prominent pre-trained Transformers like BERT, GPT-2, XLNet, Megatron-LM, Turing-NLG, T5, and GPT-3 have significantly advanced NLP. However, their size poses challenges, consuming substantial memory, computation, and energy. This becomes more pronounced when targeting devices with lower capacity, such as smartphones or applications necessitating rapid responses, like interactive chatbots.
To contextualize, training GPT-3, a potent and sizable Transformer model, on 300 billion tokens costs well over 12 million USD. Moreover, utilizing such models for fine-tuning or inference demands high-performance GPU or multi-core CPU clusters, incurring significant monetary expenses. Model compression offers a potential remedy.
Breakdown of BERT
Bidirectional Encoder Representations from Transformers, commonly known as BERT, constitutes a Transformer-based model that undergoes pre-training using extensive datasets sourced from Wikipedia and the Bookcorpus dataset. This pre-training involves two key objectives:
- Masked Language Model (MLM): These objectives aid BERT in grasping sentence context by learning to predict masked-out words within the text.
- Next Sentence Prediction (NSP): BERT also learns relationships between two sentences through NSP, which predicts whether one sentence follows the other in a given text.
Subsequent iterations of Transformer architectures have refined these training objectives, resulting in enhanced training techniques.
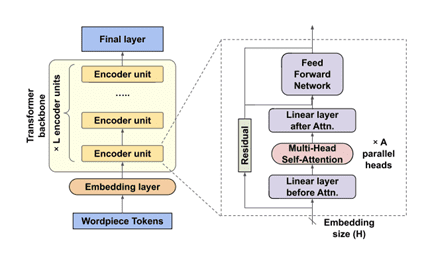
Fig. BERT model
The processing flow of the BERT model divides input sentences into WordPiece tokens, a type of tokenization that strengthens input vocabulary representation while condensing its size. Subworlds are used to break apart complex words to do this. Notably, these subworlds can create new words not in the training set, strengthening the model’s resistance to terms that aren’t in its lexicon. BERT is characterized by a classification token ([CLS]) before input tokens. The output corresponding to this token is used for tasks aiming at the whole input. Sentence pairs involved in situations are concatenated with a separator character ([SEP]) between them.
Each WordPiece token in BERT is encoded using three vectors: ticket, segment, and position embeddings. These embeddings are summed and fed through the model’s core, the Transformer backbone. This results in output representations directed into the final layer, tailored to the specific application (for instance, a sentiment analysis classifier).
The Transformer backbone comprises stacked encoder units, each featuring two primary sub-units: a self-attention sub-unit and a feed-forward network (FFN) sub-unit. Both sub-units possess residual connections for enhanced learning. The self-attention sub-unit incorporates a multi-head self-attention layer alongside a fully connected layer before and after. Meanwhile, the FFN sub-unit exclusively employs thoroughly combined layers. Three hyper-parameters define BERT’s architecture:
- The number of encoder units (L),
- The embedding vector (H) size and the number of attention heads in each self-attention layer (A).
- L and H determine the model’s depth and width, respectively, while A, an internal hyper-parameter, influences the contextual relations each encoder focuses on.
Explore BERT Compression Techniques, for more details get in touch with us Today.
Compression Methods
Various compression methods address BERT’s complexity. Quantization reduces unique values for weights and activations, lowering memory usage and potentially enhancing inference speed. Pruning encompasses unstructured and structured approaches, removing redundant weights or architectural components. Knowledge Distillation trains smaller models using larger pre-trained models’ outputs. Other techniques like Matrix Decomposition, Dynamic Inference Acceleration, Parameter Sharing, Embedding Matrix Compression, and Weight Squeezing contribute to compression efforts.
1. Quantization
Quantization involves the reduction of unique values necessary to depict model weights and activations. This reduction enables their representation using fewer bits, leading to diminished memory usage and reduced precision in numerical computations. Quantization might enhance runtime memory consumption and inference speed, especially when the foundational computational hardware is engineered to handle lower-precision numerical values. An example is the utilization of tensor cores in recent Nvidia GPU generations. Programmable hardware like FPGAs can also be meticulously tailored to optimize bandwidth representation. Furthermore, quantization to intermediate outputs and activations can expedite model execution further.
2. Pruning
Pruning methodologies for BERT predominantly fall within two distinct categories:
(i). Unstructured Pruning: Also referred to as sparse pruning, unstructured pruning involves removing individual weights identified as least crucial within the model. The significance of these weights can be assessed based on their absolute values, gradients, or customized measurement metrics. Given BERT’s extensive employment of fully connected layers, unstructured pruning holds potential efficacy. Examples of unstructured pruning methods encompass magnitude weight pruning, which discards weights close to zero; movement-based pruning, which eliminates weights tending towards zero during fine-tuning; and reweighted proximal pruning (RPP), which employs iteratively reweighted ℓ1 minimization followed by the proximal algorithm to separate pruning and error back-propagation. Due to its weight-by-weight approach, unstructured pruning can result in arbitrary and irregular sets of pruned weights, potentially reducing the model size without significantly improving runtime memory or speed unless applied on specialized hardware or utilizing specialized processing libraries.
(ii). Structured Pruning: Structured pruning targets the elimination of structured clusters of weights or even entire architectural components within the BERT model. This approach simplifies and reduces specific numerical modules, leading to enhanced efficiency. The focal areas of structured pruning comprise Attention Head Pruning, Encoder Unit Pruning, and Embedding Size Pruning.
3. Knowledge Distillation
Knowledge Distillation involves training a compact model (referred to as the student) by utilizing outputs generated by one or more extensive pre-trained models (referred to as the teachers) through various intermediate functional components. This exchange of information might occasionally pass through an intermediary model. Within the context of the BERT model, numerous intermediate outcomes serve as potential learning sources for the student. These include the logits within the concluding layer, the outcomes of encoder units, and the attention maps.
4. Other methods
1. Matrix Decomposition
2. Dynamic Inference Acceleration
3. Parameter Sharing
4. Embedding Matrix Compression
5. Weight Squeezing
Effectiveness of Compression Methods
Quantization and unstructured pruning offer the potential to decrease the model size. Yet, their impact on runtime inference speed and memory consumption remains limited, unless applied on specialized hardware or using specialized processing libraries. Conversely, when deployed on suitable hardware, these techniques can significantly enhance speed while maintaining performance levels with minimal compromise. Therefore, it’s crucial to consider the target hardware device before opting for such compression methods in practical scenarios.
Knowledge distillation has demonstrated strong compatibility with various student models, and its unique approach sets it apart from other methods, making it a valuable addition to any compression strategy. Specifically, distilling knowledge from self-attention layers, if feasible, holds integral importance in Transformer compression.
Alternatives like BiLSTMs and CNNs boast an additional advantage in terms of execution speed compared to Transformers. Consequently, replacing Transformers with alternative architectures is a more favorable choice when dealing with stringent latency requirements. Additionally, dynamic inference techniques can expedite model execution, as these methods can be seamlessly integrated into student models sharing a foundational structure akin to Transformers.
A pivotal insight from our preceding discussion underscores the significance of amalgamating diverse compression methodologies to realize truly effective models tailored for edge environments.
Do you want to Optimize Your NLP Applications?
Applications of BERT
BERT’s capabilities are extensive and versatile, enabling the development of intelligent and efficient search engines. Through BERT-driven studies, Google has advanced its ability to comprehend the intent behind search queries, delivering relevant results with increased accuracy.
Text summarization represents another area where BERT’s potential shines. BERT can be harnessed to facilitate textual content summarization, endorsing a well-regarded framework that encompasses both extractive and abstractive summarization models. In the context of extractive summarization, BERT identifies the most significant sentences within a document, forming a summary. This involves a neural encoder creating sentence representations, followed by a classifier that predicts which sentences merit inclusion as part of the summary.
The advent of SCIBERT underscores the significance of BERT in medical literature. Given the exponential growth in clinical resources, NLP powered by SCIBERT has become a vital tool for large-scale data extraction and system learning from these documents.
BERT’s contribution extends to the realm of chatbots as well. It played a pivotal role in enhancing the Stanford Question Answering Dataset (SQuAD), which involves reading comprehension tasks based on questions posed to Wikipedia articles. Leveraging BERT’s functionality, chatbot capabilities can be extended from handling small to substantial text inputs.
Moreover, BERT’s utility encompasses sentiment analysis, which involves discerning sentiments and emotions conveyed in textual content. Additionally, BERT excels in tasks related to text matching and retrieval, where it aids in identifying and retrieving relevant textual information.