- May 31, 2024
- Posted by: Sreenivasan Rajasekaran
- Category: Gen AI

Large Language Models (LLMs) excel at providing answers based on the data they’ve been trained on, typically sourced from publicly available content. However, enterprises often seek to utilize LLMs with their proprietary data. Techniques such as LLM finetuning, Retrieval-Augmented Generation (RAG), and contextual prompt fitting offer various approaches to achieving this goal.
This article outlines the fundamentals of Retrieval-Augmented Generation (RAG) and illustrates how your data can be integrated into applications supported by Large Language Models (LLMs).
Retrieval-Augmented Generation (RAG)
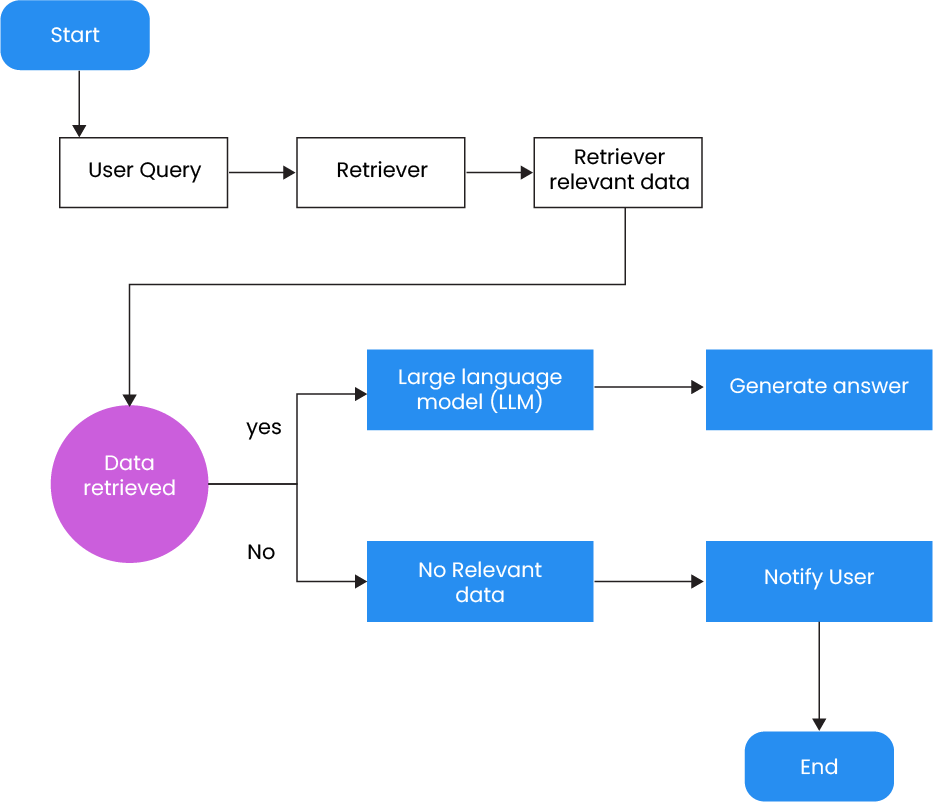
Retrieval-augmented generation (RAG) entails recovering specific data from an indexed dataset and retaining a Large Language Model (LLM) to generate an answer to a given question or task. At a high level, this process involves two main components:
- Retriever: This component recovers relevant data based on the user-provided query.
- Generator: The generator augments the retrieved data, typically by framing it within a prompt context, and then feeds it to the LLM to generate a relevant response.
History of RAG
A research article titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” written by scientists from Facebook AI Research, University College London, and New York University, is where the term “Retrieval-Augmented Generation” first appeared.
This paper presented the concept of RAG and demonstrated how it could be utilized in language generation tasks to produce more precise and accurate outputs. This work bids several positive societal benefits over earlier work: the fact that it is more strongly grounded in truthful knowledge (in this case, Wikipedia) makes it ‘hallucinate’ less with more factual groups and offers more control and interpretability,” the paper stated.
Additionally, the research highlighted that RAG could be employed in a wide variety of scenarios with direct benefit to society, for example, by endowing it with a medical index and asking it open-domain questions on that topic or helping people be more effective at their jobs.
RAG Architecture
RAG architecture consists of several core components that enable its functionality. These components include:
1. Web Server/Chatbot:
The web server hosts the chatbot interface, where users interact with the language model. Users’ prompts are passed to the retrieval model.
- Knowledge Base/Data Storage:
This component contains files, images, videos, documents, databases, tables, and other unstructured data that the LLM processes to respond to user queries.
- Retrieval Model:
The retrieval model analyses the user’s prompt using natural language processing (NLP) and seeks relevant data in the knowledge base. This data is then forwarded to the generation model.
- Generation Model:
The generation model routes the user’s initial prompt and combines the information collected by the retrieval model to generate a response, which is then sent back to the user via the chatbot interface.
Use Cases of RAG
- Customer Service: Many companies use RAG to enhance customer service by reducing wait times and improving the overall customer experience. Giving customer service professionals access to the most relevant company data can resolve issues more quickly.
- Master Data Management (MDM): RAG can greatly impact MDM by improving inventory management, consolidating sourcing contracts, and predicting inventory utilization. It also helps address customer and supplier management challenges, especially for B2C and large corporate clients with multiple legal entities.
- Operations: In operations, RAG can help speed up recovery from outages, prevent production line issues, and enhance cybersecurity measures. It also supports the adoption of AI across various operational areas, including IT operations and IoT, by utilizing data for more efficient problem-solving.
- Research/Product Development: RAG can speed up product development by identifying critical features that will significantly impact the market. It also helps engineering teams find solutions more rapidly, accelerating innovation.
How People Are Using RAG
Retrieval-augmented generation (RAG) allows users to converse with data repositories, creating new and dynamic experiences. This expands RAG’s potential applications far beyond the existing datasets.
For instance, a generative AI model enhanced with a medical index could be a valuable assistant for doctors or nurses. Similarly, financial analysts could benefit from an AI assistant connected to market data.
Nearly any business can transform its technical or policy manuals, videos, or logs into knowledge bases to enhance LLMs. These resources can be used for various purposes, such as customer or field support, employee training, and improving developer productivity.
Due to its immense potential, RAG is being adopted by organizations such as IBM, Glean, Google, AWS, Microsoft, Oracle, Pinecone, and many more.
Building User Trust
Retrieval-augmented generation (RAG) enhances user trust by providing models with sources they can cite, similar to footnotes in a research paper, allowing users to verify claims. This approach also helps models clarify ambiguous user queries and reduces the likelihood of making incorrect guesses, known as hallucinations.
Additionally, RAG is faster and more cost-effective than retraining a model with new datasets, allowing users to swap in new sources as needed easily.
RAG Challenges
While Retrieval-Augmented Generation (RAG) is a highly useful approach to AI development, it comes with several challenges. One of the primary challenges is the need to build an extensive knowledge base of high-quality content for reference.
Creating this knowledge base is complex because the data must be carefully curated. Low input data quality will negatively impact the accuracy and reliability of the output.
Additionally, developers need to address any biases or prejudices that might be present in the knowledge base.
Finally, while RAG can enhance reliability, it cannot completely eliminate the risk of hallucinations. End users still need to exercise caution when trusting the outputs.
Pros and Cons of Retrieval-Augmented Generation
RAG is a powerful tool for organizations. Below, we’ll examine some of its most notable benefits and drawbacks.
| Pros | Cons |
| Connecting to a domain-specific knowledge base improves information retrieval and reduces misinformation | without high-quality data, output quality may suffer |
| Updating the knowledge base instead of retraining the model savestime and money for developers | Building a substantial knowledge base demands significant time and organization. |
| Users gain access to citiations and references, facilitating easy fact-checking | Biases in training data can influenace outputs |
| Domain-specific outputs meet users’specialized needs more effectively | Even with improved accuracy, there remains a risk of hallucinations. |
Why Indium
As a Databricks consulting partner, Indium brings over a decade of expertise in maximizing enterprise data potential. Leveraging Databricks’ robust, flexible, and scalable platform, our services span the entire data analytics spectrum, ensuring seamless integration and management.
Our accelerator, ibriX, enhances data integration and management capabilities, accelerating your enterprise’s data transformation. Our services include Databricks consulting, cloud migration, lakehouse development, data engineering on Databricks, and advanced analytics, AI, and ML solutions.
Working with Indium guarantees a thorough approach to data transformation, utilizing state-of-the-art tools and customized solutions to advance your company. For more details, reach us.
Wrapping Up
Retrieval-augmented generation (RAG) is a valuable technology for enhancing an LLM’s core capabilities. With the right knowledge base, organizations can equip users with access to a wealth of domain-specific knowledge.
However, users must remain proactive about fact-checking outputs for hallucinations and other mistakes to prevent misinformation.
FAQs
Retrieval-augmented generation occurs when a language model is connected to an external knowledge base, which retrieves data to respond to user queries.
RAG can be connected to various information sources, including documents, files, databases, news sites, social media posts, etc.
RAG is a technique developers use to feed data into generative AI applications. These applications utilize natural language processing (NLP) and natural language generation (NLG) to produce content responding to user prompts. While closely related, they are not the same.
In the context of Large Language Models (LLMs), RAG refers to the process where the language model processes user requests against an external knowledge base and responds to user queries with information retrieved from within that dataset.